SEO uitbesteden? Wij zijn hét bureau voor jou!
Jouw bedrijf bovenaan in de zoekresultaten van Google? Dat kan! Onze SEO specialisten ontzorgen jou, zodat jij je weer bezig kunt houden met waar je goed in bent. Benieuwd naar ons SEO traject? Check hieronder alle info!

Organisch groeien door het uitbesteden van SEO
De wereld van Google en organische vindbaarheid kan voelen als een oneindige rabbit hole. Waar kun je het beste beginnen en hoe kom je zo snel mogelijk bij het bereiken van jouw doelen. Look no further, want wij hebben de oplossing voor jou: SEO! Bij Red Banana ben je aan het juiste adres voor het uitbesteden van jouw SEO. Keer op keer weten wij door onze jarenlange kennis en ervaring de Google-formule voor onze klanten te ontcijferen. Dit doen wij door het schrijven van krachtige teksten en het implementeren van de juiste keywords.
Maar, bij Red Banana gaan we verder dan dat! Wanneer je jouw SEO laat uitbesteden door ons, mag je rekenen op een sterke en effectieve SEO strategie met een focus op content creatie. Hoe wij dat doen? Dat lees je hieronder. Ben jij klaar voor organische groei met behulp van SEO? We drinken graag een bakkie met je!

Websites en webshops die gevonden worden
Bij Red Banana hebben we 15+ jaar ervaring in het ontwikkelen van professionele WordPress websites en Lightspeed webshops. Het is dan ook geen wonder dat onze Banana’s precies weten aan welke knoppen zij moeten draaien om een webshop hoger in Google te krijgen. De combinatie van developers en content marketeers in ons team maakt dat onze webshops in de basis al goed staan, en dus geïndexeerd worden door Google.
Als webshop eigenaar is het de uitdaging om hoog in de zoekresultaten van potentiële bezoekers te staan. Met het uitbesteden van SEO door Red Banana gaan we die uitdaging samen met jou aan.
Keyword research: het startpunt van je SEO-strategie
Een SEO-strategie zonder keyword research is als een banaan zonder zijn bananenplant. De fundering ontbreekt. Daarom starten we bij Red Banana altijd met een uitgebreid zoekwoordenonderzoek. We denken na over de zoekwoorden waar jij op gevonden wilt worden. En misschien nog wel belangrijker, we onderzoeken waar de doelgroep naar op zoek is. Welke keywords gebruiken zij tijdens het zoeken naar jouw producten of diensten?
Met een zoekwoordenonderzoek inventariseren we de kansen voor het kraken van de Google-code. Door een flinke dosis kennis over SEO, Google en websites komen we tot een goede lijst met keywords.

SEO uitbesteden door Red Banana. Dit zijn de voordelen:
-
Ruim 10 jaar ervaring met SEO en content marketing
-
Diepe kennis van zoekmachine optimalisatie
-
Een doeltreffende aanpak met als resultaat meer relevant verkeer
-
Kansen inventariseren aan de hand van een uitgebreid zoekwoordenonderzoek
-
SEO met een focus op het creëren van content die echt gelezen wordt
-
24/7 monitoring van posities in zoekmachines met een hands-on mentaliteit voor het doorvoeren van optimalisaties
-
Korte lijntjes met onze experts: wij houden het graag laagdrempelig en persoonlijk
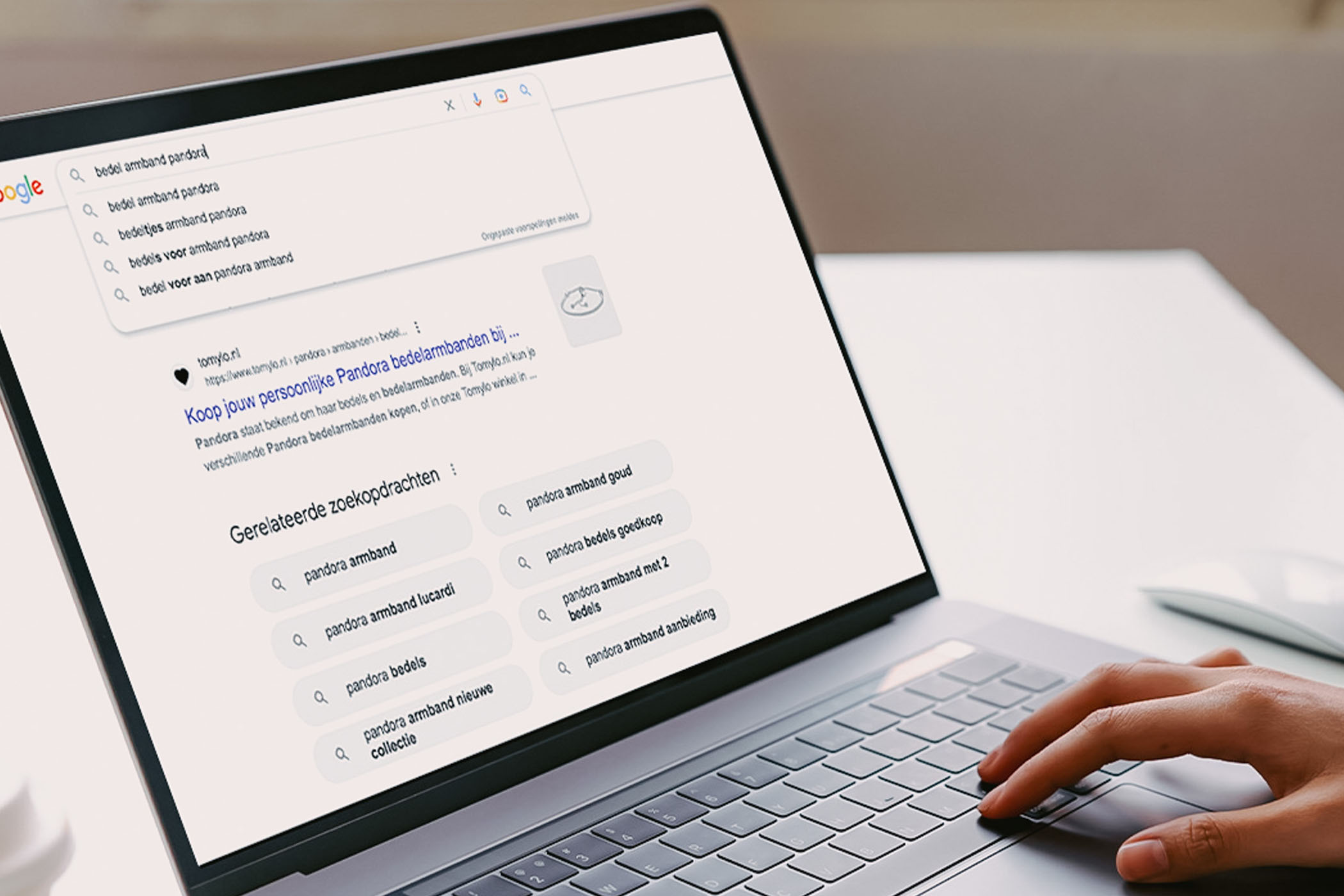
SEO advies van een online marketing bureau met ervaring
Het schrijven van teksten zit in ons DNA. Dit heeft onder meer te maken met onze afkomst. Red Banana is ontstaan vanuit The Blog Idea Factory, één van de grootste blognetwerken van Nederland. Hierdoor weten wij als geen ander hoe belangrijk het is om online gevonden te worden. Organische vindbaarheid zorgt namelijk voor meer traffic en helpt bij het online opbouwen van autoriteit. In een wereld waar de concurrentie moordend is, helpen wij natuurlijk graag met het bereiken van organisch succes.
Aan de hand van een uitgebreide analyse van de concurrentie en het zoekwoordenonderzoek, helpen wij de laag hangende bananen te vinden. Dit zijn kansen die voor het grijpen liggen en die op korte termijn al bijdragen aan online vindbaarheid. Tegelijkertijd denken we met je mee aan jouw toekomstige doelen en ambities. Een SEO traject vraagt om een lange termijn strategie, en wij voorzien je graag van professioneel advies!
Content creatie met een SEO focus
Het creëren van unieke en creatieve content is wat we bij Red Banana doen en waar we blij van worden. Voor ons is dit de basis voor de online vindbaarheid van jouw webshop of website. Het schrijven van creatieve teksten zit in ons DNA, en dat weet Google ook. Wij maken content die aansluit bij jouw doelgroep. Tegelijkertijd bevatten onze teksten alle nodige informatie die Google nodig heeft bij het beoordelen van een pagina. Van de juiste zoekwoorden tot aan technische SEO settings en linkbuilding.
Wij nemen de SEO werkzaamheden voor jouw website of webshop graag voor je uit handen. Benieuwd wat een SEO traject voor jou kan betekenen? Kom eens een bakkie drinken!

Een greep uit onze projecten
SEO trajecten waar we trots op zijn!
Een succesvolle SEO-strategie voor iedere webshop of website.

SEO uitbesteden? Zo bouwen wij aan een succesvolle SEO-strategie!
SEO adviesplan
-
Samen stellen we de juiste KPI's op
-
We voeren een nulmeting uit op de huidige website of webshop
-
We analyseren de organische posities van concurrenten
-
We bepalen de potentie van zoekwoorden aan de hand van keyword research
-
Aan de hand van alle analyses brengen we de doelgroep in kaart
Planning & Clustering
-
Selectie van de belangrijkste pagina's op basis van zoekvolume en relevantie
-
Content clusteren aan relevante categorieën
-
We bespreken jouw wensen omtrent de belangrijkste pagina's
-
We stellen een SEO planning op
-
We bespreken de SEO planning en verwerken eventuele feedback
Content creatie
-
We optimaliseren de huidige menustructuur
-
We maken categoriepagina's van de belangrijkste thema's
-
We voorzien de belangrijkste categorieën van SEO teksten
-
Google knows: we voorzien afbeeldingen van de juiste titels
-
We zetten alle SEO settings per pagina goed
Monitoren & Optimaliseren
-
Organische posities monitoren met onze SEO tools
-
We voeren technische optimalisaties door
-
We voeren on-page optimalisaties door
-
Starten met linkbuilding
-
Doorlopend uitvoeren van optimalisatie werkzaamheden
Wat is SEO en waarom is het zo belangrijk voor jouw website of webshop?
Voor veel mensen voelt Google als een magische plek waar de regels iedere dag lijken te veranderen. SEO (Search Engine Optimization) is een vorm van marketing die je helpt om met de juiste technieken, en volgens de regels, beter gevonden te worden in zoekmachines. En dat is vandaag de dag belangrijker dan ooit! Wist je dat 90% van alle Nederlanders een zoektocht naar een dienst, product of bedrijf beginnen in Google? En dat de conversiepercentages vanuit organisch verkeer vaak beter zijn dan vanuit bijvoorbeeld social media?
Bij Red Banana kennen we onze zoekmachine-vrienden als de binnenkant van onze broekzak. Wij weten keer op keer de geheime Google-formule te ontcijferen en maken daarbij gebruik van de beste tools. En dat is niet alles. Ons team van content marketeers en SEO-experts kunnen de gehele online marketing voor jouw bedrijf uit handen nemen. Red Banana is jouw one-stop-shop voor online succes met behulp van content marketing!
Dit zeggen onze klanten
Bij Red Banana kun je rekenen op een snelle service. Ze zijn altijd bereikbaar, toegankelijk, hebben kennis van zaken en zijn professioneel.
In een branche waar veel ondernemers schreeuwen dat ze beste zijn, laat Red Banana zien dat zij het zijn. Als lokale ondernemer staan we nu boven de landelijke ketens en ook de andere vestigingen in Nederland stijgen naar de plaats waar we moeten staan. Kortom een betrouwbare partij waar je op kan bouwen.
Ik werk al jaren samen met Red Banana. Van de ontwikkeling van custom tools tot aan goede SEO teksten en blogs: ik ben dik tevreden met mijn webshop!

Alle SEO-ingrediënten in één webshop
Heb je behoefte aan een nieuwe webshop die meteen gevuld wordt met sterke SEO-content? Dan hebben we een heerlijke Smooothie webshop voor jou! Smooothie is een onderdeel van Red Banana. Zie het als een framework waarin jarenlange kennis van design, development, content en user experience gebundeld is. Een perfecte smoothie, of zoals wij hem noemen: Smooothie, met een extra dimensie, zoals alleen Red Banana’s die kunnen toevoegen. Smooothie is gebouwd met Lightspeed. Herkenbaar, betrouwbaar en razendsnel. Geoptimaliseerd op gebruiksvriendelijkheid, conversies en natuurlijk vindbaarheid.
Wil jij ook een professionele website laten maken die goed scoort in zoekmachines als Google? Neem dan vandaag nog contact met ons op en vraag vrijblijvend een offerte aan. Wij helpen je graag verder!

Wat kost het om SEO uit te besteden?
Wat ben je kwijt voor een SEO traject? Het eerlijke antwoord: SEO is maatwerk. Afhankelijk van jouw wensen en ambities (en natuurlijk je portemonnee) denken wij mee over een traject dat passend is. Hierdoor zijn er geen vaste bedragen te noemen. Het is maar net wat je ervoor over hebt. Houd er wel rekening mee dat je naast de maandelijkse SEO werkzaamheden ook te maken hebt met eenmalige kosten voor het uitwerken van het SEO adviesplan en het vooronderzoek dat daarbij hoort.
Na het SEO adviesplan kunnen we starten met on page en off page SEO optimalisaties. De on page SEO omvat het verwerken van de juiste zoekwoorden in websiteteksten, meta titles en descriptions en foto’s of video’s. De off page SEO gaat meer over alles dat buiten je website of webshop aan SEO wordt gedaan. Denk aan persberichten, blogs schrijven en social media berichten maken.
De prijs voor een SEO traject wordt bij Red Banana bepaald aan de hand van beschikbare uren. Dit wordt van te voren en in overleg gedaan. Zo weet je altijd wat het kost om je SEO uit te besteden. Ook weten wat het uitbesteden van SEO kost? Neem vrijblijvend contact op voor een offerte op maat!
Professioneel SEO bureau in Roosendaal
Wil je online beter gevonden worden en ben je op zoek naar een manier om meer bezoekers naar je webshop te halen? Dan past het SEO traject van Red Banana perfect bij jou! Door het schrijven van goede SEO webteksten, sterke copywriting en blogs helpen onze Bananas je om hoger te scoren in Google. Je hebt ons nu al gevonden, dus waarom zou je nog verder zoeken?
Bij Red Banana denken we verder dan SEO. Als allround online marketing bureau ben je bij ons aan het juiste adres voor het uitbesteden van social media management, social advertising, e-mailmarketing en natuurlijk SEO. Wil je liever een professionele webshop of website laten maken? Doen we ook! Ons kantoor is gunstig gelegen in het altijd zonnige Roosendaal. Vanuit Antwerpen (België) en Breda, Tilburg en Eindhoven bereik je ons makkelijk via de A58. Kom je van de andere kant? Vanuit Utrecht en Rotterdam bezoek je ons via de A17. Niks staat je nog in de weg. Dus kom gezellig langs of drink online een bakkie met ons!
SEO staat voor Search Engine Optimization, ook wel zoekmachineoptimalisatie genoemd. Het omschrijft marketingwerkzaamheden die bijdragen aan een betere organische vindbaarheid in zoekmachines zoals Google.
Het toepassen van SEO in jouw website of webshop helpt je om een hogere plaats te bemachtigen in de zoekresultaten van Google. Ruim één op de drie gebruikers van Google klikt op de eerste link van de organische zoekresultaten. Zorg dus dat je hier tussen staat! Dooe onze SEO specialisten aan de juiste knoppen te laten draaien, en te focussen op lange termijn succes, zul je zien dat een betere organische vindbaarheid leidt tot meer conversie, meer omzet en meer winst.
SEO is iets dat je best zelf kunt doen. Bedenk wel dat dit hetzelfde is als een huis bouwen. Je kunt er best aan beginnen, maar om het goed te doen heb je up-to-date kennis nodig. Er zijn continu veranderingen binnen dit vakgebied. Wij raden daarom altijd aan om SEO specialisten het werk te laten doen.
Bij Red Banana zeggen we weleens: "Als je iets wilt verstoppen, moet je het op de tweede pagina in Google zetten. Daar kijkt toch niemand." Klinkt hard, maar het is helaas wel de waarheid. Gemiddeld zoekt een bezoeker niet verder dan de eerste 10 zoekresultaten in Google. Hoe hoger je staat, hoe sneller iemand op je website of webshop klikt. En we weten allemaal: hoe meer bezoekers, hoe groter de kans op conversie.
Ons team van getalenteerde bloggers, copywriters en ghostwriters schrijft niet alleen SEO teksten voor een betere vindbaarheid, maar ook blogs. Bloggen is namelijk goed voor je organische vindbaarheid. Iedere pagina met inhoud kan door een zoekmachine worden geïndexeerd. Het geeft een extra lading aan je SEO teksten. Hierdoor kan bloggen zeker bijdragen aan SEO.
Door een pagina van goede in- en uitgaande links te voorzien, creëren we als het ware een web van content. Zonder de links is een pagina opzichzelfstaand. Google houdt niet van zwevende pagina's. Daarom clusteren we bij Red Banana content. Dit doen we door hoofdcategorieën en subcategorieën te voorzien van SEO teksten, en tegelijkertijd blogs te schrijven en social berichten over dat onderwerp te plaatsen.
Je SEO uit laten besteden? Neem vrijblijvend contact op met Bohdy
